|
OpenLB 1.7
|
Loading...
Searching...
No Matches
|
OpenLB 1.7
|
CUDA kernels to execute collisions and post processors. More...
Functions | |
| template<typename CONTEXT , typename FIELD > | |
| void | gather_field (CONTEXT lattice, const CellID *indices, std::size_t nIndices, typename FIELD::template value_type< typename CONTEXT::value_t > *buffer) __global__ |
| CUDA kernel for gathering FIELD data of lattice at indices into buffer. | |
| template<typename SOURCE , typename TARGET , typename FIELD > | |
| void | copy_field (SOURCE sourceLattice, TARGET targetLattice, const CellID *sourceIndices, const CellID *targetIndices, std::size_t nIndices) __global__ |
| CUDA kernel for copying FIELD data of sourceLattice at sourceIndices into targetLattice at targetIndices. | |
| __global__ void | gather_any_fields (AnyDeviceFieldArrayD *fields, std::size_t nFields, const CellID *indices, std::size_t nIndices, std::uint8_t *buffer) |
| CUDA kernel for gathering fields at indices into buffer. | |
| __global__ void | copy_any_fields (AnyDeviceFieldArrayD *sourceFields, AnyDeviceFieldArrayD *targetFields, std::size_t nFields, const CellID *sourceIndices, const CellID *targetIndices, std::size_t nIndices) |
| CUDA kernel for copying sourceFields at sourceIndices to targetFields at targetIndices. | |
| template<typename CONTEXT , typename FIELD > | |
| void | scatter_field (CONTEXT lattice, const CellID *indices, std::size_t nIndices, typename FIELD::template value_type< typename CONTEXT::value_t > *buffer) __global__ |
| CUDA kernel for scattering FIELD data in buffer to indices in lattice. | |
| __global__ void | scatter_any_fields (AnyDeviceFieldArrayD *fields, std::size_t nFields, const CellID *indices, std::size_t nIndices, std::uint8_t *buffer) |
| CUDA kernel for scattering fields in buffer to indices in lattice. | |
| template<typename CONTEXT , typename... OPERATORS> | |
| void | call_operators (CONTEXT lattice, bool *subdomain, OPERATORS... ops) __global__ |
| CUDA kernel for applying purely local collision steps. | |
| template<typename CONTEXT , typename... OPERATORS> | |
| void | call_operators_with_statistics (CONTEXT lattice, bool *subdomain, OPERATORS... ops) __global__ |
| CUDA kernel for applying purely local collision steps while tracking statistics. | |
| template<typename CONTEXT , typename... OPERATORS> | |
| void | call_list_operators (CONTEXT lattice, const CellID *indices, std::size_t nIndices, OPERATORS... ops) __global__ |
| CUDA kernel for applying generic OPERATORS with OperatorScope::PerCell or ListedCollision. | |
| template<typename CONTEXT , typename... OPERATORS> | |
| void | call_list_operators_with_statistics (CONTEXT lattice, const CellID *indices, std::size_t nIndices, OPERATORS... ops) __global__ |
| CUDA kernel for applying ListedCollision. | |
| template<typename CONTEXTS , typename... OPERATORS> | |
| void | call_coupling_operators (CONTEXTS lattices, bool *subdomain, OPERATORS... ops) __global__ |
| CUDA kernel for applying UnmaskedCoupling(WithParameters) | |
| template<typename T , typename DESCRIPTOR , typename DYNAMICS , typename PARAMETERS = typename DYNAMICS::ParametersD> | |
| void | construct_dynamics (void *target, PARAMETERS *parameters) __global__ |
| CUDA kernel for constructing on-device ConcreteDynamics. | |
CUDA kernels to execute collisions and post processors.
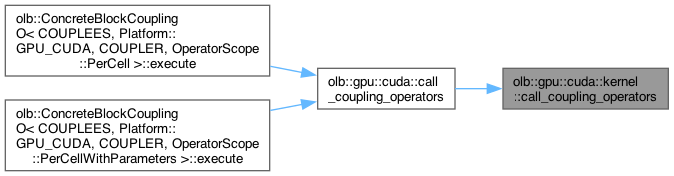
| void olb::gpu::cuda::kernel::call_coupling_operators | ( | CONTEXTS | lattices, |
| bool * | subdomain, | ||
| OPERATORS... | ops ) |
CUDA kernel for applying UnmaskedCoupling(WithParameters)
Definition at line 341 of file operator.hh.
 Here is the caller graph for this function:
Here is the caller graph for this function:| void olb::gpu::cuda::kernel::call_list_operators | ( | CONTEXT | lattice, |
| const CellID * | indices, | ||
| std::size_t | nIndices, | ||
| OPERATORS... | ops ) |
CUDA kernel for applying generic OPERATORS with OperatorScope::PerCell or ListedCollision.
Definition at line 301 of file operator.hh.
Here is the caller graph for this function:| void olb::gpu::cuda::kernel::call_list_operators_with_statistics | ( | CONTEXT | lattice, |
| const CellID * | indices, | ||
| std::size_t | nIndices, | ||
| OPERATORS... | ops ) |
CUDA kernel for applying ListedCollision.
Statistics data is reduced by StatisticsPostProcessor
Definition at line 316 of file operator.hh.
References olb::CellStatistic< T >::rho.
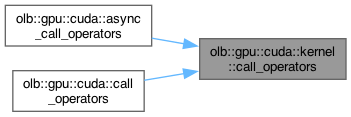
| void olb::gpu::cuda::kernel::call_operators | ( | CONTEXT | lattice, |
| bool * | subdomain, | ||
| OPERATORS... | ops ) |
CUDA kernel for applying purely local collision steps.
Definition at line 265 of file operator.hh.
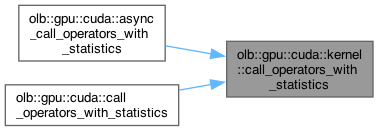
Here is the caller graph for this function:| void olb::gpu::cuda::kernel::call_operators_with_statistics | ( | CONTEXT | lattice, |
| bool * | subdomain, | ||
| OPERATORS... | ops ) |
CUDA kernel for applying purely local collision steps while tracking statistics.
Statistics data is reduced by StatisticsPostProcessor
Definition at line 278 of file operator.hh.
References olb::CellStatistic< T >::rho.
Here is the caller graph for this function:| void olb::gpu::cuda::kernel::construct_dynamics | ( | void * | target, |
| PARAMETERS * | parameters ) |
CUDA kernel for constructing on-device ConcreteDynamics.
Definition at line 352 of file operator.hh.
| __global__ void olb::gpu::cuda::kernel::copy_any_fields | ( | AnyDeviceFieldArrayD * | sourceFields, |
| AnyDeviceFieldArrayD * | targetFields, | ||
| std::size_t | nFields, | ||
| const CellID * | sourceIndices, | ||
| const CellID * | targetIndices, | ||
| std::size_t | nIndices ) |
CUDA kernel for copying sourceFields at sourceIndices to targetFields at targetIndices.
source and target fields may be of different block lattices but must represent the same field types in the same sequence
Definition at line 145 of file communicator.hh.
| void olb::gpu::cuda::kernel::copy_field | ( | SOURCE | sourceLattice, |
| TARGET | targetLattice, | ||
| const CellID * | sourceIndices, | ||
| const CellID * | targetIndices, | ||
| std::size_t | nIndices ) |
CUDA kernel for copying FIELD data of sourceLattice at sourceIndices into targetLattice at targetIndices.
Definition at line 106 of file communicator.hh.
| __global__ void olb::gpu::cuda::kernel::gather_any_fields | ( | AnyDeviceFieldArrayD * | fields, |
| std::size_t | nFields, | ||
| const CellID * | indices, | ||
| std::size_t | nIndices, | ||
| std::uint8_t * | buffer ) |
CUDA kernel for gathering fields at indices into buffer.
Definition at line 122 of file communicator.hh.
| void olb::gpu::cuda::kernel::gather_field | ( | CONTEXT | lattice, |
| const CellID * | indices, | ||
| std::size_t | nIndices, | ||
| typename FIELD::template value_type< typename CONTEXT::value_t > * | buffer ) |
CUDA kernel for gathering FIELD data of lattice at indices into buffer.
Definition at line 91 of file communicator.hh.
| __global__ void olb::gpu::cuda::kernel::scatter_any_fields | ( | AnyDeviceFieldArrayD * | fields, |
| std::size_t | nFields, | ||
| const CellID * | indices, | ||
| std::size_t | nIndices, | ||
| std::uint8_t * | buffer ) |
CUDA kernel for scattering fields in buffer to indices in lattice.
Definition at line 182 of file communicator.hh.
| void olb::gpu::cuda::kernel::scatter_field | ( | CONTEXT | lattice, |
| const CellID * | indices, | ||
| std::size_t | nIndices, | ||
| typename FIELD::template value_type< typename CONTEXT::value_t > * | buffer ) |
CUDA kernel for scattering FIELD data in buffer to indices in lattice.
Definition at line 168 of file communicator.hh.