|
OpenLB 1.7
|
Loading...
Searching...
No Matches
|
OpenLB 1.7
|
Load balancer for heterogeneous CPU-GPU systems. More...
#include <heterogeneousLoadBalancer.h>
 Inheritance diagram for olb::HeterogeneousLoadBalancer< T >: Collaboration diagram for olb::HeterogeneousLoadBalancer< T >:
Inheritance diagram for olb::HeterogeneousLoadBalancer< T >: Collaboration diagram for olb::HeterogeneousLoadBalancer< T >:Public Member Functions | |
| HeterogeneousLoadBalancer (CuboidGeometry< T, 3 > &cGeometry, T largeBlockFraction=0.9) | |
| Platform | platform (int loc) const override |
| void | setPlatform (int loc, Platform platform) |
| Public Member Functions inherited from olb::LoadBalancer< T > | |
| LoadBalancer (int size=1) | |
| Default empty constructor. | |
| LoadBalancer (int size, std::map< int, int > &loc, std::vector< int > &glob, std::map< int, int > &rank) | |
| Constructor accepting existing balancing. | |
| LoadBalancer (int size, std::map< int, int > &loc, std::vector< int > &glob, std::map< int, int > &rank, std::map< int, Platform > &platform) | |
| Constructor accepting existing heterogeneous balancing. | |
| virtual | ~LoadBalancer () |
| Default empty destructor. | |
| void | swap (LoadBalancer< T > &loadBalancer) |
| Swap method. | |
| bool | isLocal (const int &glob) |
returns whether glob is on this process | |
| int | loc (const int &glob) |
| int | loc (int glob) const |
| int | glob (int loc) const |
| int | rank (const int &glob) |
| int | rank (int glob) const |
| int | size () const |
| int | getRankSize () const |
| bool | operator== (const LoadBalancer< T > &rhs) const |
| equal operator | |
| std::size_t | getNblock () const override |
| Number of data blocks for the serializable interface. | |
| std::size_t | getSerializableSize () const override |
| Binary size for the serializer. | |
| bool * | getBlock (std::size_t iBlock, std::size_t &sizeBlock, bool loadingMode) override |
| Return a pointer to the memory of the current block and its size for the serializable interface. | |
| void | print (bool multiOutput=false) const |
| Public Member Functions inherited from olb::Serializable | |
| virtual | ~Serializable ()=default |
| template<bool includeLogOutputDir = true> | |
| bool | save (std::string fileName="", const bool enforceUint=false) |
Save Serializable into file fileName | |
| template<bool includeLogOutputDir = true> | |
| bool | load (std::string fileName="", const bool enforceUint=false) |
Load Serializable from file fileName | |
| bool | save (std::uint8_t *buffer) |
Save Serializable into buffer of length getSerializableSize | |
| bool | load (const std::uint8_t *buffer) |
Load Serializable from buffer of length getSerializableSize | |
| virtual void | postLoad () |
Additional Inherited Members | |
| Protected Member Functions inherited from olb::BufferSerializable | |
| template<typename DataType > | |
| void | registerSerializable (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, size_t &sizeBufferIndex, bool *&dataPtr, DataType &data, const bool loadingMode=false) |
Register Serializable object of dynamic size. | |
| template<typename DataType > | |
| void | registerStdVectorOfVars (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, size_t &sizeBufferIndex, bool *&dataPtr, std::vector< DataType > &data, const bool loadingMode=false) |
Method for registering a std::vector<DataType> of primitive DataType (int, double, ...) | |
| template<typename DataType > | |
| void | registerStdVectorOfSerializablesOfConstSize (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, size_t &sizeBufferIndex, bool *&dataPtr, std::vector< DataType > &data, const bool loadingMode=false) |
Method for registering a std::vector<DataType> of constant-sized Serializable | |
| template<typename DataType > | |
| void | registerStdVectorOfSerializables (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, size_t &sizeBufferIndex, bool *&dataPtr, std::vector< DataType > &data, const bool loadingMode=false) |
Method for registering a std::vector<DataType> of dynamic-sized DataType | |
| template<typename DataTypeKey , typename DataTypeValue > | |
| void | registerMap (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, size_t &sizeBufferIndex, bool *&dataPtr, std::map< DataTypeKey, DataTypeValue > &data, const bool loadingMode=false) |
Method for registering a std::map<DataTypeKey, DataTypeValue> of fixed-sized types (i.e. int, double) | |
| size_t | addSizeToBuffer (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, size_t &sizeBufferIndex, bool *&dataPtr, const size_t data) const |
Add a size_t to the sizeBuffer in the n-th util::round and return that size_t in all successive rounds. | |
| Protected Member Functions inherited from olb::Serializable | |
| template<typename DataType > | |
| void | registerVar (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, bool *&dataPtr, const DataType &data, const size_t arrayLength=1) const |
Register primitive data types (int, double, ...) or arrays of those. | |
| template<typename DataType > | |
| void | registerSerializableOfConstSize (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, bool *&dataPtr, DataType &data, const bool loadingMode=false) |
Register Serializable object of constant size. | |
| template<typename DataType > | |
| void | registerSerializablesOfConstSize (const std::size_t iBlock, std::size_t &sizeBlock, std::size_t ¤tBlock, bool *&dataPtr, DataType *data, const size_t arrayLength, const bool loadingMode=false) |
Register an array of Serializable objects of constant size. | |
| Protected Attributes inherited from olb::LoadBalancer< T > | |
| int | _size |
| number of cuboids after shrink -1 in appropriate thread | |
| std::map< int, int > | _loc |
| maps global cuboid to (local) thread cuboid | |
| std::vector< int > | _glob |
| content is 0,1,2,...,_size | |
| std::map< int, int > | _rank |
| maps global cuboid number to the processing thread | |
| std::map< int, Platform > | _platform |
| maps global cuboid number to local platform | |
| Protected Attributes inherited from olb::BufferSerializable | |
| std::vector< bool * > | _dataBuffer |
Data buffer for data that has to be buffered between two getBlock() iterations. | |
| std::vector< size_t > | _sizeBuffer |
std::vector of integer buffers (e.g. for std::vector size) to be buffered for the whole iteration process | |
Load balancer for heterogeneous CPU-GPU systems.
Assigns largest cuboids to GPUs until given largeBlockFraction is reached. Remaining (small) cuboids are assigned to CPUs of their GPU-placed neighbors.
This balancer should only be used in conjunction with a heterogeneous cuboid decomposition and appropriate, system specific, CPU_SIMD+OpenMP configuration.
Definition at line 45 of file heterogeneousLoadBalancer.h.
|
inline |
Definition at line 50 of file heterogeneousLoadBalancer.h.
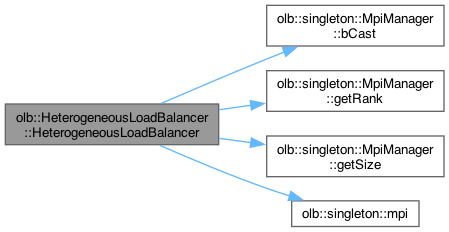
References olb::LoadBalancer< T >::_glob, olb::LoadBalancer< T >::_loc, olb::LoadBalancer< T >::_rank, olb::LoadBalancer< T >::_size, olb::singleton::MpiManager::bCast(), olb::CPU_SIMD, olb::CPU_SISD, olb::singleton::MpiManager::getRank(), olb::singleton::MpiManager::getSize(), olb::GPU_CUDA, and olb::singleton::mpi().
Here is the call graph for this function:
|
inlineoverridevirtual |
Reimplemented from olb::LoadBalancer< T >.
Definition at line 189 of file heterogeneousLoadBalancer.h.
References olb::LoadBalancer< T >::loc().
Here is the call graph for this function: Here is the caller graph for this function:
|
inlinevirtual |
Reimplemented from olb::LoadBalancer< T >.
Definition at line 193 of file heterogeneousLoadBalancer.h.
References olb::LoadBalancer< T >::loc(), and olb::HeterogeneousLoadBalancer< T >::platform().
Here is the call graph for this function: