Following up on the performance-focused release of OpenLB 1.5 we updated our Performance showcases to include scalability plots on up to 128 CPU-only resp. Multi-GPU nodes of the HoreKa supercomputer at the Karlsruhe Institute of Technology (KIT). These results were presented at the 25th Results and Review Workshop of the HLRS this October and are accepted for publication in the annual proceedings on High Performance Computing in Science and Engineering.
The following plots document the per-node performance in Billions of Cell Updates per Second (GLUPs) for various problem sizes of the established lid driven cavity benchmark case. Highlights include weak scaling efficiencies up to 1.01 for hybrid AVX-512 vectorized CPU resp. up to 0.9 for CUDA GPU execution alongside a total peak performance of 1.33 Trillion Cell Updates per Second when using 512 NVIDIA A100 GPUs. Further details including individual strong scaling values are available in the performance section.
Scalability of OpenLB 1.5 on HoreKa using hybrid execution (MPI + OpenMP + AVX-512 Vectorization)

Scalability of OpenLB 1.5 on HoreKa using multi GPU execution (MPI + CUDA)
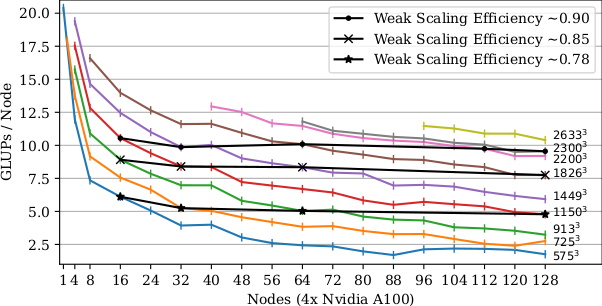
Plots, vectorization and CUDA GPU implementation contributed by Adrian Kummerländer.
A. Kummerländer, F. Bukreev, S. Berg, M. Dorn and M.J. Krause. Advances in Computational Process Engineering using Lattice Boltzmann Methods on High Performance Computers for Solving Fluid Flow Problems. In: High Performance Computing in Science and Engineering ’22 (accepted).