…on HoreKa using OpenLB 1.5 (2022)
Following the release of OpenLB 1.5, the parallel performance was evaluated on the HoreKa supercomputer at the Karlsruhe Institute of Technology (KIT) This showcases the current performance-focused execution capabilities of OpenLB, including the usage of Nvidia GPUs (CUDA) and vectorization (AVX2/AVX-512) on CPUs.
The following plots document the per-node performance in Billions of Cell Updates per Second (GLUPs) for various problem sizes of the established lid driven cavity benchmark case with non-local boundary treatment. All simulations used a single-precision D3Q19 lattice with BGK collision and Periodic Shift streaming. GPU simulations used up to 512 Nvidia A100 GPUs on 128 nodes of HoreKa’s accelerated partition and resulted in a maximum observed total performance of ~1.33 Trillion Cell Updates per Second (TLUPs).
For comparison, performance of a more involved turbulent nozzle flow case using interpolated boundaries and LES modelling was found to correspond well to these ideal benchmark results at e.g. 92% of the lid driven cavity reference on 224 A100 GPUs using the same number of cells.
A. Kummerländer, F. Bukreev, S. Berg, M. Dorn and M.J. Krause. Advances in Computational Process Engineering using Lattice Boltzmann Methods on High Performance Computers for Solving Fluid Flow Problems. In: High Performance Computing in Science and Engineering ’22 (accepted).
Scalability of OpenLB 1.5 on HoreKa using hybrid execution (MPI + OpenMP + AVX-512 Vectorization)

Strong efficiencies in [32,128]: 575³ : 0.66, 725³: 0.83, 913³ : 0.76, 1150³ : 0.75, 1449³ : 0.76, 1826³: 0.79, 2200³ : 0.84
Strong efficiencies in [64,128]: 575³: 0.78, 725³ : 0.96, 913³ : 0.94, 1150³ : 0.89, 1449³ : 0.86, 1826³: 0.89, 2200³: 0.91
Scalability of OpenLB 1.5 on HoreKa using multi GPU execution (MPI + CUDA)
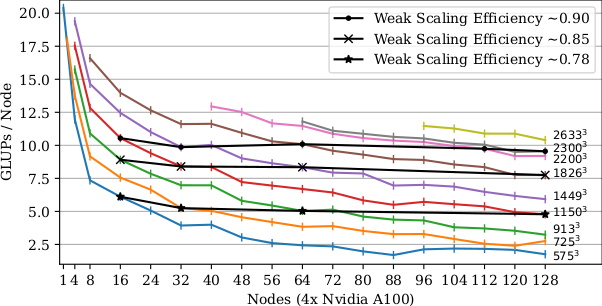
Strong efficiencies in [32,128]: 575³ : 0.45, 725³ : 0.53, 913³ : 0.46, 1150³ : 0.57, 1449³ : 0.6, 1826³ : 0.67
Strong efficiencies in [64,128]: 575³ : 0.72, 725³ : 0.72, 913³: 0.64, 1150³ : 0.71, 1449³ : 0.71, 1826³: 0.77, 2200³: 0.8, 2300³ : 0.81
A detailed discussion of the employed Periodic Shift streaming pattern is available in:
A. Kummerländer, M. Dorn, M. Frank and M.J. Krause. Implicit propagation of directly addressed grids in lattice Boltzmann methods. In: Concurrency and Computation. DOI: 10.1002/cpe.7509 (open access)
Plots, vectorization and CUDA GPU implementation contributed by Adrian Kummerländer.
…on Pawsey Magnus using OpenLB 1.3 (2018)
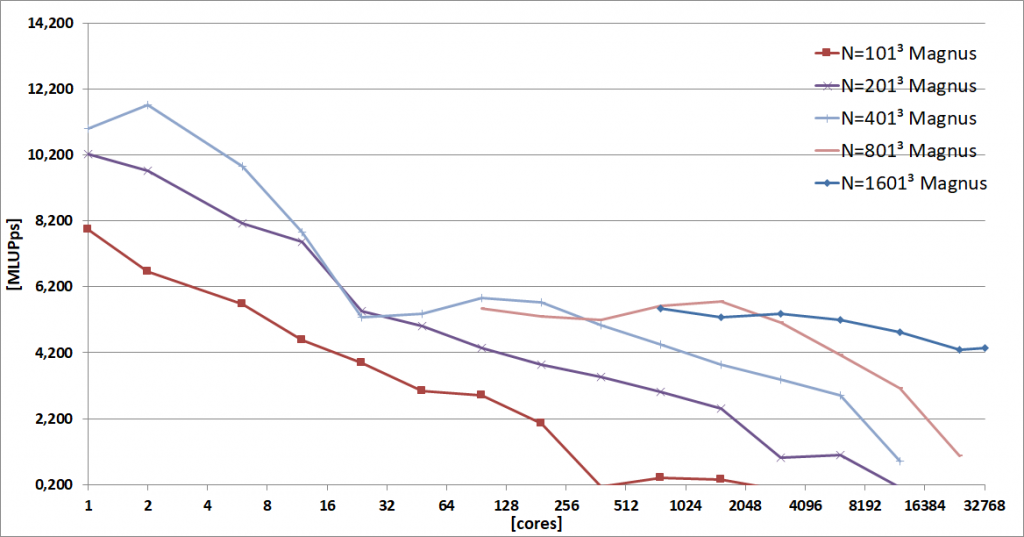
In a joint project of the Lattice Boltzmann Research Group (LBRG) at the Karlsruhe Institute of Technology (KIT) and the Fluid Dynamics Research Group (FDRG) of the Curtin Institute for Computation (CIC, Curtin University), OpenLB was tested, profiled and improved on the Pawsey Magnus super computer (TOP500 at 358 Nov. 2018) and then applied to large scale fliter simulations. This represents one of the largest scale CFD simulations in the world.

The performance of OpenLB was evaluated for a realistic scenarios at the Magnus super computer (TOP500 at 358 Nov. 2018) using up to 32,784 of the available 35,712 cores obtaining 142,479 MLUPs. That are about 142 billion fluid cells which were updated in one second using OpenLB on Magnus. This proves the computational efficiency and scalability of OpenLB, which will allow it to solve some of the largest and most important fluid flow problems relevant to process engineering and a range of other fields.
More information:
Contributed by Mathias J Krause, Andrew JC King, Nima Nadim, Maciej Cytowski, Shiv Meka, Ryan Mead-Hunter, Hermann Nirschl and Benjamin J Mullins